Solution:
mmap() is used to
remap physical memory and files into a process's virtual address space. It is
widely used when linking shared libraries, since they don't have to be loaded
into process' memory. mmap can also be used to map a file on the disk to the
virtual
address space of several processes. When a file is accessed by one of the
processes, it will be loaded into the physical memory and it will not be loaded
twice when other processes need it, since those processes can access the files
through their virtual memory mappings.
mprotect controls access permissions to a section of memory.
Here is the detailed information about these functions copied from the man pages.
The prot argument describes the desired memory protection. It has bits:
The munmap system call deletes the mappings for the specified address range, and causes further references to addresses within the range to generate invalid memory references.
prot is a bitwise-or of the following values:
As seen from the man page descriptions, to be able to use mmap and mprotect we need to know a file descriptor and the length of file section we want to map starting from the offset. For our purposes, the offset from the file is going to be 0 and the length of the section we want to access is as large as the file itself. In order to get the file descriptor, we can use open() system call and, for finding out the length of the file we can use fstat(). You can find the detailed descriptions of these system calls in man pages. I'll give a brief summary of these system calls here:
#include <sys/types.h> #include <sys/stat.h>
#include <fcntl.h>
int open(const char * pathname , int flags );
open attempts to
open a file and return a file descriptor (a small, non-negative integer for use
in read , write , etc.)
flags is one of
O_RDONLY , O_WRONLY or O_RDWR which request opening the file read-only,
write-only or read/write, respectively.
#include <sys/stat.h>
#include <unistd.h>
fstat(int filedes , struct stat * buf );
stats the file pointed to by filedes and fills in buf
struct stat
{
dev_t st_dev; /* device */
ino_t st_ino; /* inode */
mode_t st_mode; /* protection */
nlink_t st_nlink; /* number of hard links */
uid_t st_uid; /* user ID of owner */
gid_t st_gid; /* group ID of owner */
dev_t st_rdev; /* device type (if inode device) */
off_t st_size; /* total size, in bytes */
unsigned long st_blksize; /* blocksize for filesystem IO */
unsigned long st_blocks; /* number of blocks allocated */
time_t st_atime; /* time of last access */
time_t st_mtime; /* time of last modification */
time_t st_ctime; /* time of last change */
};
Now we can write pseudo code for the brokers and the manager
assuming that mentioned file is Stock.data.
Broker() {
//open the file in read only mode and get the file descriptor
int fd = open( "Stock.data", O_RDONLY );
//get the information about the file
struct stat* this_file = new struct stat;
fstat( fd, this_file);
//now let's map the file into the process' virtual memory space
void* addr = (void*)mmap( Null, this_file->off_t,PROT_READ,MAP_SHARED, fd, 0);
/* DO SOMETHING*/
munmap(addr, this_file->off_t );
return;
}
Manager() {
//open the file in read only mode and get the file descriptor
int fd = open( "Stock.data", O_RDWR
//get the information about the file
struct stat* this_file = new struct stat;
stat( fd, this_file);
//now let's map the file into the process' virtual memory space
void* addr = mmap( Null, this_file->off_t,PROT_READ | PROT_WRITE,MAP_SHARED, fd, 0);
/* DO SOMETHING*/
/* WRITE*/
/* DO SOMETHING*/
munmap(addr, this_file->off_t );
return;
}
The disk controller needs a physical memory address, not a virtual address. Ben Bitdiddle proposes that when the user does a write system call, the operating system should check that the user's virtual address is valid, translate it into a physical address, and pass that address and the length (also checked for validity) to the disk hardware.
This won't quite work. In no more than two sentences, what did Ben forget?
Solution:
Need solution
Each disk rotates at 10000 RPM and takes 5 ms on an average random seek. There are on average 300 sectors per track and each sector is 512 bytes (in actuality, the number of sectors per track will vary, but we'll ignore that. We'll also assume that each request is entirely contained in one track and that each starts at a random sector location on the track.)
To access disk, the CPU overhead is 30 microseconds to set up a disk access. The disk DMAs data directly to memory, so there is no CPU per-byte cost for disk accesses.
Each network interface has a bandwidth of 100 Mbits/s (that's Mbits not MBytes!) and there is a 4 millisecond one-way network latency between a client and the server. The network interface is full-duplex: it can send and receive at the same time at full bandwidth. The CPU has an overhead of 100 microseconds to send or receive a network packet. Additionally, there is a CPU overhead of .01 microseconds per byte sent.
So, a disk can support up to 100 requests per second.
(Note a slight simplifying assumption: we ignore the effect that a track buffer might have. A track buffer would sometimes overlap some of the rotation time and some of the BW time by letting the read begin at the "end" of the 50KB chunk, wait for the beginning part to come around, and be done when the beginning part has been read...)
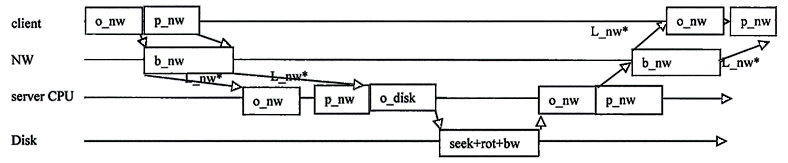
*L_nw: how to pipeline? Here, I assume the (unrealistic) best case scenario: the CPU starts processing the packet when the first byte arrives and finishes processing the last byte just as the last byte arrives. Other reasonable assumptions would be to not start processing the packet once it has entirely arrived. In reality, a large NW send (like 50KB) would be broken into smaller packets, each of which would be processed once it has entirely arrived to get pipelining, but each also would pay an overhead.Each arrow shows a dependency in time (the tail must happen before the head).
Total time on critical path is
o_nw + b_nw(128) + L_nw+ o_disk + seek + rot + bw + o_nw + b+nw(50x2^10) + L_nw = 100x10-6 + 128 bytes * 1 second/100x10^6 bits * 8 bits/byte + 4x10-3 + 30x10-6 + 100x10-6 + 50x2^10 * 1 second/100x10^6 bits * 8 bits/byte = 8.336ms
Solution:
False.