Automatically Compiling a Validation Set from Google's Image Search
Overview
One of the main problems in learning from Google is that there are no images possessing labels that can be trusted. Hence it is very difficult to make important decisions concerning model structure which would normally be made by a validation set. Here we present a way to generate a small set of images which empirically show a far greater portion of "good" images than is typical for a dataset. While not big enough to train a model from, it is sufficient to act as a noisy validation set.
Empirical Observations about Images Returned by Google
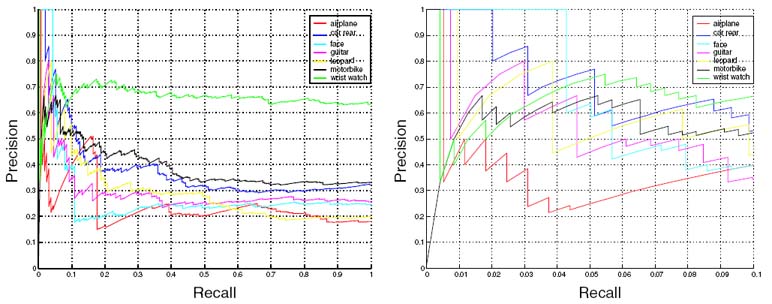
Below we show the recall precision curves of the raw output of Google. Note that the quality of images returned is markedly higher at low recall. Why this should be the case is not entirely clear, perhaps the frequency of selection by web users is being used by Google to re-order the images. Zooming (the figure on the right), we can see that the performance starts dropping very quickly - below a recall of 0.02 or so. With around 500 images being gathered per query, this corresponds to around 10 images. This is before the end of the first page (25 images) and not enough even for a validation set.
Translating the Keyword
The query provided by the user is the only reliable piece of information we have. We take this keyword and use Google's automatic translation tool to translate it into 6 other languages (French, Spanish, Italian, German, Portuguese and Chinese). Since the query words will typically be nouns, the translation tool proves to be quite reliable in operation. For example, the word "airplane" is translated as (Avion, Aeroplano, Aeroplano, Flugzeug, Aviao, <Can't type it, sorry>), in the 6 languages respectively. The idea is that although a similar drop off in precision vs recall will occur for each language, by taking the very first few images from each language's output, we can amass a sufficiently large number to have a sensible validation set. In our experiments, we used the first 5 images from each language, giving between 25 and 35 images (sometimes the word was the same in two or more languages). Note that the entire procedure is automatic.
Examples
Below on the left we see a typical page of images returned by Google for the query "airplane". On the right is the validation set obtained as described above. While there are still junk images, there are roughly double the number of good images than in the typical sample.


Below we show a typical sample of motorbike images and the motorbike validation set.

